Кодировка
Будет уместнее, если мы будем рассматривать электронный текст как последовательность байтов. Ключевым моментом здесь является то, сколько байт выделяется для хранения 1 символа текста. По историческим причинам широкое распространение получили т.н. восьмибитные кодировки, в которых для хранения 1 символа текста использовали 1 байт памяти.
Кодировка (кодовая таблица) - это однозначное соответствие между последовательностью целых чисел и некоторым набором символов. На практике, последовательность чисел - это числа от 0 до 255, а набор символов - строчные и прописные буквы некоторого алфавита, цифры, знаки пунктуации и т.п.
По все тем же историческим причинам одной из первых кодировок, получивших широкое распространение, была кодировка ASCII (американский стандартный код обмена информацией) (см. табл. ниже). Первые 128 знакомест в ней занимали все строчные и прописные буквы английского алфавита, цифры от 0 до 9, знаки пунктуации и различные управляющие символы. Данную кодировку еще называют 7-битной кодировкой т.к. для кодирования 128 (от 0 до 127) символов вполне хватает 7 бит. Старший же 8-ой бит занулялся.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | SPC | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | — | . | / |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Дело в том, что большинство известных миру кодировок - это потомки ASCII. Они расширили данную кодировку путем задействования старшего 8-го бита. Т.е. диапазон знакомест от 128 до 255 программисты использовали для кодирования своих национальных символов. Отсюда и вытекает факт существования бесчисленного множества кодировок. Из этого множества кодировок для нас имеют значение лишь кириллические:
- windows-1251 (обычно используется в ОС Windows)
- koi8-r (Unix / Linux)
- cp-866(альтернативная) (MS DOS)
Посмотрим на схему отображения электронного текста:
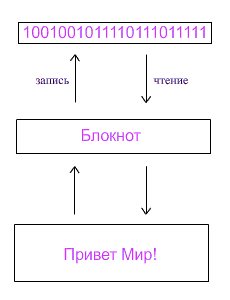
Последовательность байтов, представляющих собой текст, в определенной кодировке.
Очевидно, что ключевую роль в хранении и представлении электронного текста играет кодировка. Программа, отображающая текст, не зная исходной кодировки текста (если в ней не заложены эвристические алгоритмы распознавания кодировки, как например, в современных интернет-браузерах) отобразит вам лишь множество кракозябр.
В наши дни все большее распространение получают т.н. юникодовые кодировки.